
Google Unveils Real-Time Speech Translation With Two-Second Delay
Google’s latest breakthrough in speech-to-speech translation (S2ST) has been unveiled with the launch of a new end-to-end model designed to deliver real-time translated audio in the speaker’s own voice with only a two-second delay. The technology has been deployed in Google Meet and made available on the new Pixel 10 devices, marking a significant shift from older translation systems that required four to five seconds and often produced less natural output.
The innovation has been developed to overcome long-standing challenges in multilingual communication. In earlier cascaded systems, speech had been converted to text, translated and then generated as audio, which frequently led to compounded errors and slower responses. The new model has been designed to function as a single unified architecture, allowing translation to be produced directly from the audio stream without intermediate text steps that traditionally caused delays.
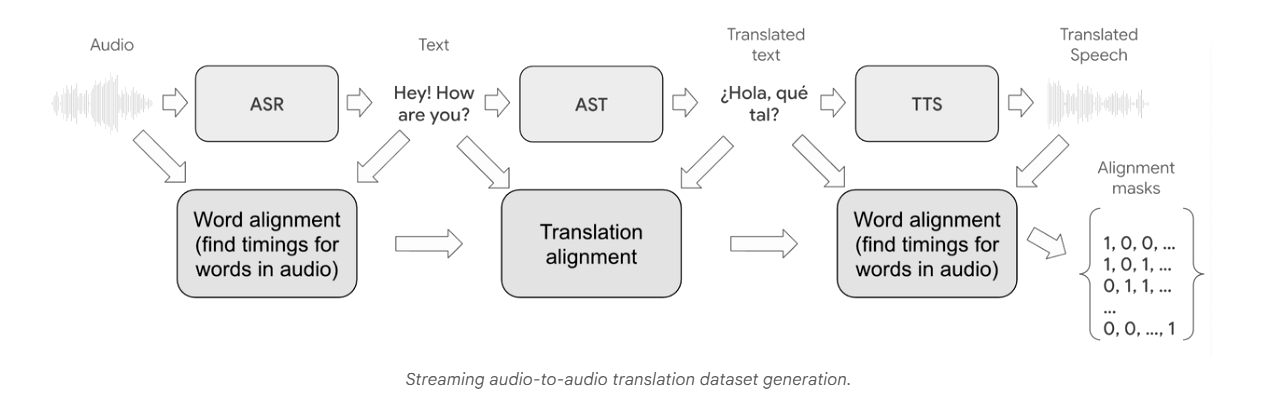
A scalable and time-synchronised data acquisition pipeline has been created for training the model. Raw audio from diverse sources has been processed, transcribed and machine-translated, followed by forced alignment to ensure accurate mapping between the original and translated speech. Audio clips with poor alignment or excessive delay have been removed. Various audio augmentations — including reverberation, denoising and sample-rate modifications — have been applied to improve performance in real-world environments.
The S2ST system has been built on a streaming encoder–decoder architecture, using transformer blocks and the SpectroStream codec to represent audio as compact tokens. These tokens have been generated sequentially to produce translated speech that retains the speaker’s original tone and voice characteristics. Techniques such as low-bit quantisation and precomputation have been employed to reduce latency and enable uninterrupted real-time output.
Support has initially been provided for five major Latin-based language pairs: English with Spanish, German, French, Italian and Portuguese. Google has indicated that early results for languages such as Hindi are promising and that work is being undertaken to expand coverage further. A two-second lookahead has been set as the standard delay, although longer lookahead settings can be used where language structure requires additional context.
The company has stated that the technology is expected to offer several benefits to the public, including more natural cross-language conversations, fewer translation errors, smoother communication during online meetings and improved accessibility for users unfamiliar with certain languages. The system is also expected to be useful during travel, education, customer support and emergency response situations. Voice preservation has been highlighted as a key advantage, as translated speech is produced in the speaker’s own voice rather than through generic text-to-speech systems.
However, limitations have also been acknowledged. The current language range remains narrow, and translation accuracy may be affected by strong accents, overlapping speech or noisy surroundings. Privacy concerns regarding synthetic voice generation have been raised, along with potential risks of misuse. The system’s availability is currently restricted to platforms such as Google Meet and devices like the Pixel 10. Server-based translation continues to require stable internet connectivity.
Despite these challenges, Google has stated that the technology represents a major step toward seamless global communication. Further refinements, including dynamic lookahead adjustments, are being planned to improve contextual understanding for languages with significantly different sentence structures.